
이번 글까지는 파이썬 코드가 등장하지 않는다.
사실 다 써놓고 보니 너무 조악해서 안 보고 넘어가도 좋을 것 같다.
크롤링의 기초와 HTML 구조를 파악하여 어떻게 접근할 지 구상하는 것이 이번 글의 목표이다.
그리고 최종 목적은 네이버증권의 테마별 종목과 테마명을 크롤링하여 엑셀에 저장하는 것까지이다.
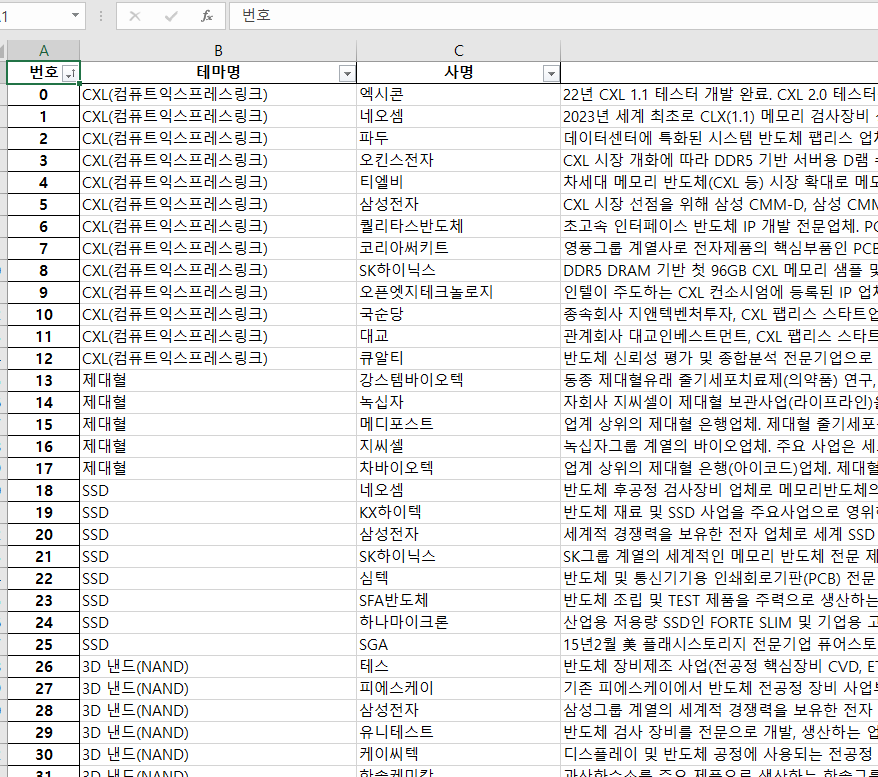
그러기위해 네이버증권의 웹페이지를 살펴보자.
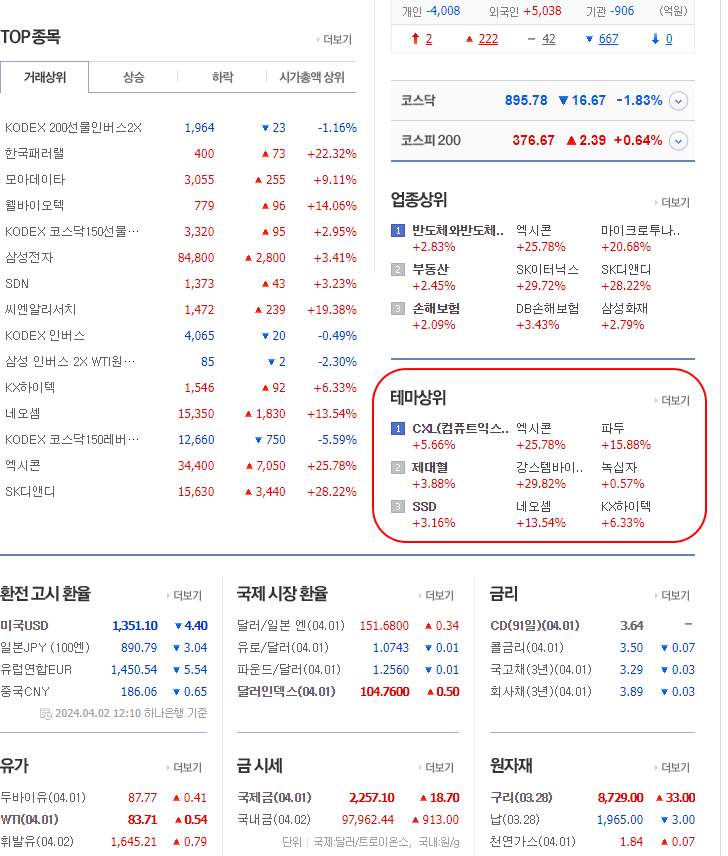
여기에서 우리가 관심있는 것은 테마이다. 더보기를 누르면 수많은 테마가 있는데 약 2024년 기준 약 283개이다.
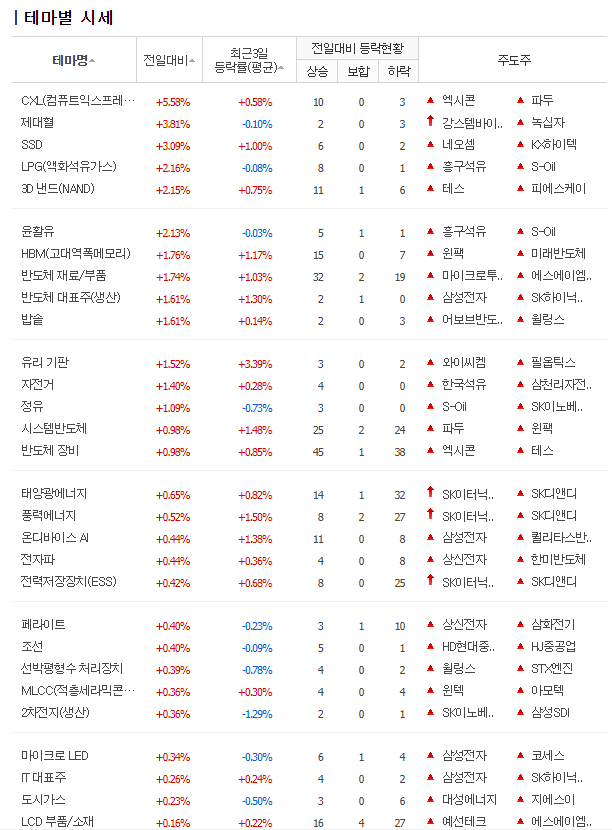
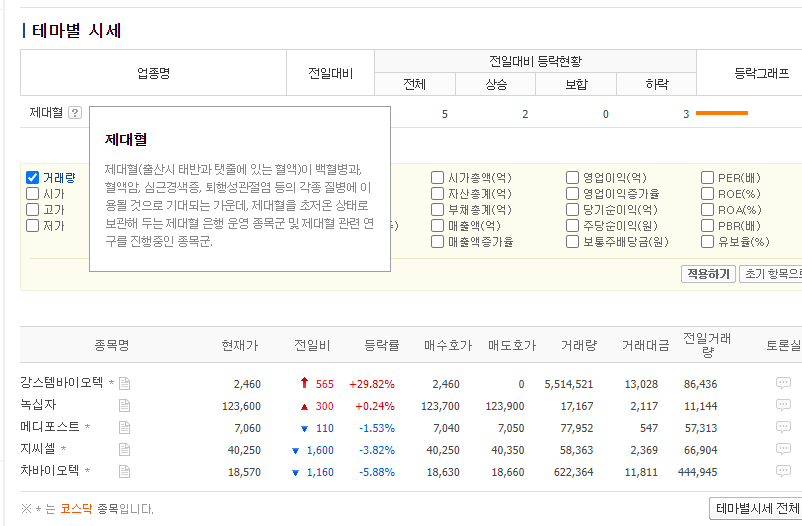

처음보는 단어인 ‘제대혈’ 테마를 눌러서 물음표에 마우스를 올리면 제대혈에 대한 설명이 뜬다.
종목명 옆의 문서모양에 마우스를 올리면 해당 종목이 해당 테마로 분류된 이유를 서술한다.
약 280개 테마가 있고 한 테마는 2~141개의 종목이 있는데 종목을 다 모으면 중복된 회사를 포함하여 6000개 이상의 회사와 설명 데이터를 얻을 수 있다.


테마 메인 페이지의 url은 위와 같은데 맨 아래의 1페이지를 한번 더 누르면 &page=1이 뜬다.
맨 뒤의 숫자만 바꾸면 쉽게 접근할 수 있다는 것을 알 수 있다.

제대혈 테마를 누르면 url은 위와 같다. 제대혈 테마의 테마 넘버는 124번. 이 역시 맨 뒤의 테마 넘버만 바꾸면 쉽게 접근할 수 있다.
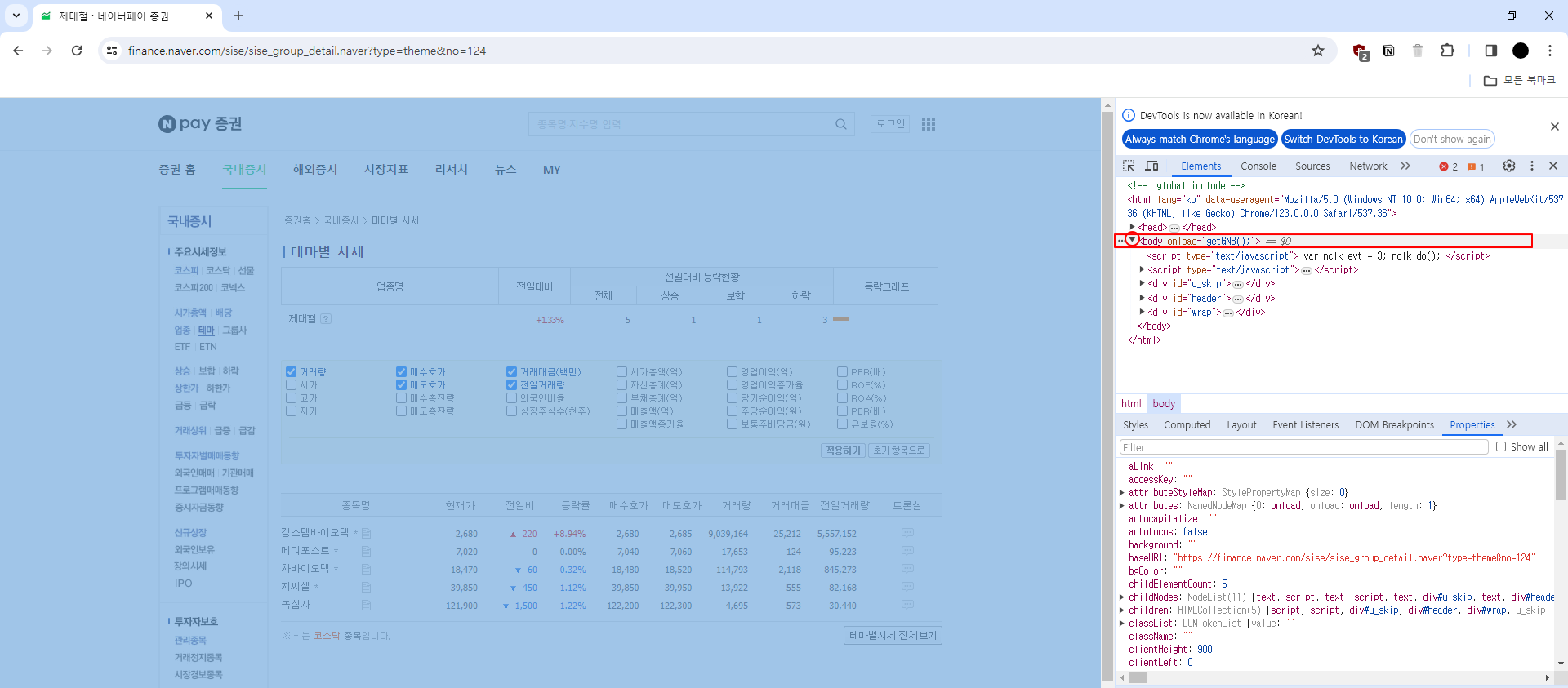
테마별 시세 페이지에서 우리의 친구 F12를 누르면 개발자도구가 뜨는데,
여기서 Elements의 <body onload=”getGNB();”> 에 커서를 올리면 화면에서 해당하는 부분이 표시된다.
화살표를 눌러서 확장하면 더 디테일한 부분을 확인할 수 있다.
내가 찾고 싶은 것은, 제대혈의 물음표에 해당하는 부분과 종목명에서 서류모양의 표시 텍스트이다.
계속해서 화살표를 누르면서 범위를 좁혀나가면 금방 찾을 수 있다.
onload -> wrap -> newarea -> contentarea -> box_type_l -> table summary="업종별 시세 리스트" -> tbody(여기서 colgroup 아님 주의)
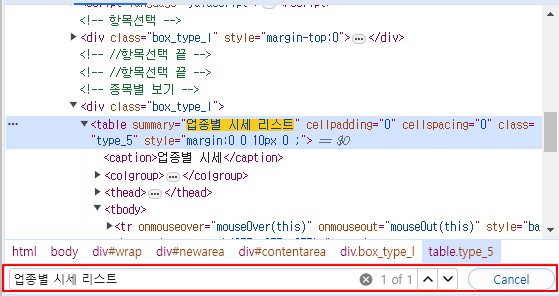
혹시 위 방법이 무슨 소리인지 모르겠으면 ctrl+F를 눌러서 ‘업종별 시세 리스트’를 검색하면 바로 찾을 수 있다.
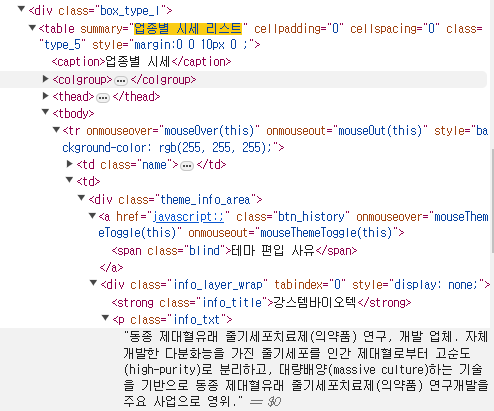
tbody에서 <tr onmouseover>의 한 줄이 종목 한 줄의 정보인 것을 알 수 있다.
여기서 쭉쭉 내리면서 찾다보면 <a href>에 히든버튼이 있고 그 아래로는 확장되지 않는데 여기는 내가 찾는 텍스트가 없다.
그래서 아랫쪽을 좀 더 보면 <div class=”info_layer_wrap> → <p class=”info_txt”>라는 탭 안에 내가 찾는 종목 정보가 있다.
사실 가장 쉽게 찾는 법은 처음부터 ctrl+F를 눌러서 “동종 제대혈유래 줄기세포치료제~~~”를 검색하면 바로 나올 것이고 어느 태그에 있는지 바로 알 수 있다.
이제 URL 구조도 알았고, HTML구조도 파악했으니 코드로 추출해보자.
(제대혈이 뭔지에 대한 텍스트 정보는 파악하지 않았지만 다음 글에 후술)
'파이썬' 카테고리의 다른 글
| [외전] 네이버증권 테마종목 크롤링 (4) 엑셀 다루기 (0) | 2024.04.06 |
|---|---|
| [파이썬] 네이버증권 테마종목 크롤링 (3) List → DataFrame → Excel (0) | 2024.04.06 |
| [파이썬] 네이버증권 테마종목 크롤링 (2-2) beautifulsoup4 크롤링 (0) | 2024.04.06 |
| [파이썬] 네이버증권 테마종목 크롤링(2-1) beautifulsoup4 크롤링 (0) | 2024.04.06 |
| [파이썬] 네이버증권 테마종목 크롤링 (0) 업로드 계기 및 잡설 (1) | 2024.04.06 |


